Wer bin ich?

-
Max Maischein
-
DZ BANK Frankfurt
-
Deutsche Zentralgenossenschaftsbank
-
Informationsmanagement TxB
Mein Leitmotiv
Automation

-
Wenn ich es von Hand kann
-
... kann der Computer es wiederholen
-
... jedesmal korrekt
Meine Umgebung
DZ BANK AG
Intranet Automation und Scraping (WWW::Mechanize::Firefox)
Meine Umgebung
DZ BANK AG
Intranet Automation und Scraping (WWW::Mechanize::Firefox)

-
Leute fragen nach Web Scraping
-
Leute fragen nach HTML Parsern
Aspekte des Web Scrapings

Nicht alles, was technisch möglich ist, ist auch erlaubt oder erwünscht
-
Können wir Scraping vermeiden?
1: Datenbankzugriff 2: Datenbankdump
-
Ist Scraping erlaubt?
1: Nutzungsbedingungen (TOS) 2: Gelten die für uns?
Vorgehen

-
Welche Schritte führt ein Mensch durch
-
->Navigation -
->Inhalt/Datenextraktion -
Automatisieren
-
Wiederholen
Webseite

Webseite
Firebug

Firebug
-
Add-on für Firefox
-
Visuelles Werkzeug um Seitenelemente zu untersuchen
Unser Ziel
Nachrichten extrahieren
Erster CSS Selector
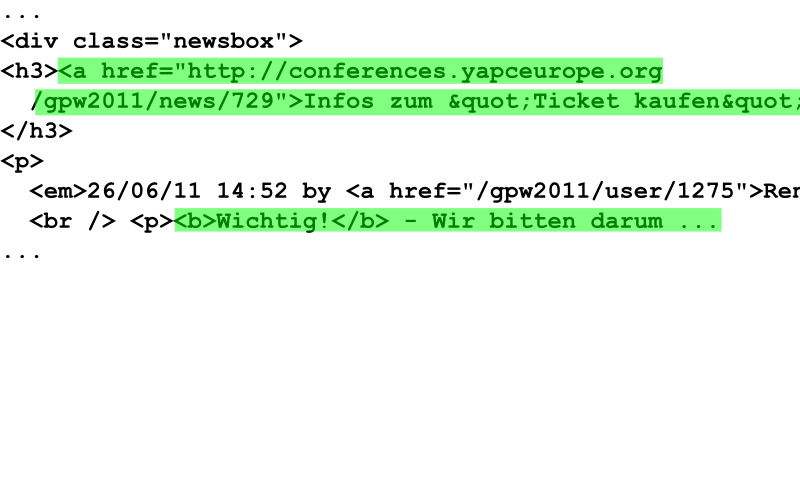
1: .newsbox
Verfeinerter CSS Selector
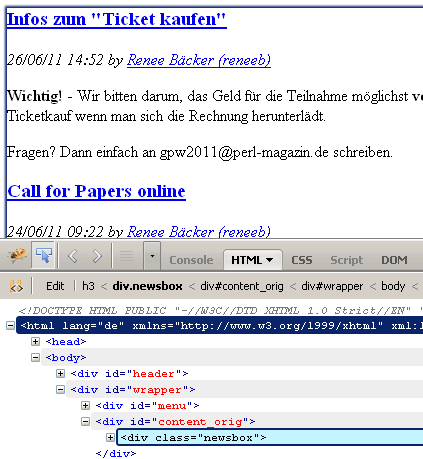
1: .newsbox h3 a
Verfeinerter CSS Selector
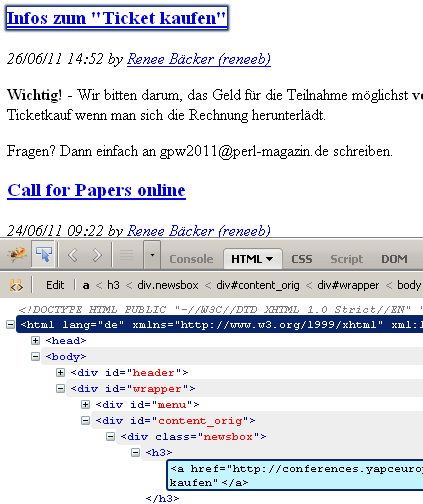
1: .newsbox h3 a
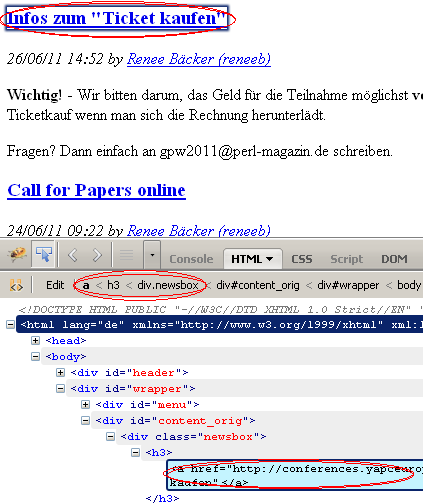
Verfeinerter CSS Selector
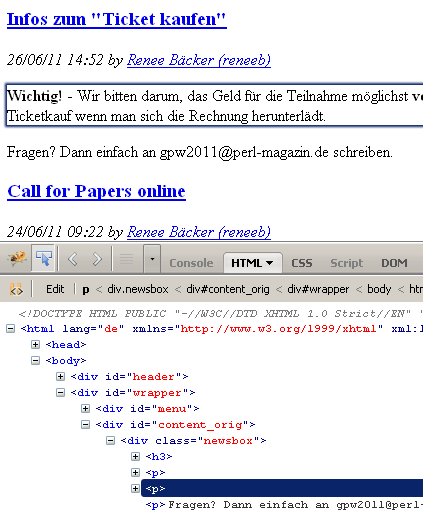
1: .newsbox h3 a 2: Call for Papers online
Verfeinerter CSS Selector
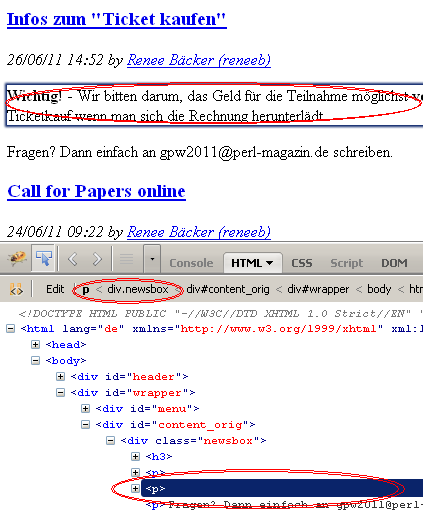
1: .newsbox h3 a 2: Call for Papers online 3: 4: .newsbox h3+p+p 5: Endlich ist es so weit ...
Komplexere Beispielsituation (Wikipedia)

-
Bilder der (DC) Superhelden von Wikipedia extrahieren
-
Input: Name des Superhelden
-
Output: URL des Bilds (oder Bilddaten) des Superheldenbilds
-
und Beschreibung
Suchfeld ausfüllen
-
Feld finden
1: search
Suchfeld ausfüllen
-
Feld finden
1: search
-
Feldnamen finden
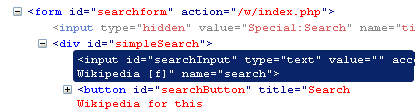
Suchfeld ausfüllen
-
Feld finden
1: search
-
Feldnamen finden
1: submit_form( with_fields => {
2: search => $hero,
3: });
Bild finden
-
Bild-Selektor finden (Firebug, ...)
1: .infobox a.image img
-
Extrahieren
1: print $_->{src} 2: for selector('.infobox a.image img'); 3: 4: # http://upload.wikimedia.org/wikipedia/en/thumb/7/72/Superman.jpg/250px-Superman.jpg
Beispiel: Extraktion von Google+ Profilen

-
Google+ is Googles Social Network
-
Mittlerweile gibt's eine API
Schritte
-
Google+ nach dem Namen suchen
-
Information aus dem Profil extrahieren
-
Die "Leute in Circles" extrahieren
Webseite
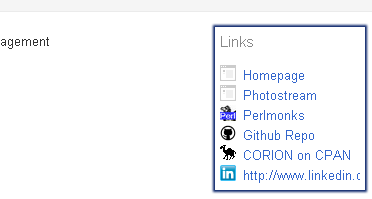
1: <h2 class="a-b-D-Nd-aa d-q-p">Links</h2> 2: <ul class="a-b-D-G-lg Nd"> 3: <li><img alt="" class="a-b-D-Mf" src="113231249772841733835_files/favicons_007.png"> 4: <div class="a-b-D-k k"><a class="a-b-D-k-cg url" href="http://corion.net/" 5: ...
"Related" Links finden
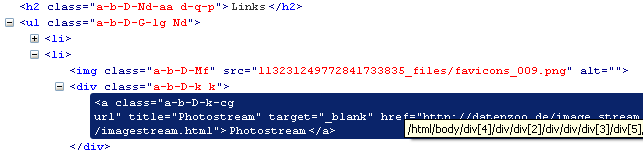
"Related" Links finden
1: div.k a.url
2:
3: my @links = selector('div.k a.url');
4:
5: for my $link (@links) {
6: print $link->{innerHTML}, "\n";
7: print $link->{href}, "\n";
8: print "\n";
9: };
Kontakte in "Circles" finden
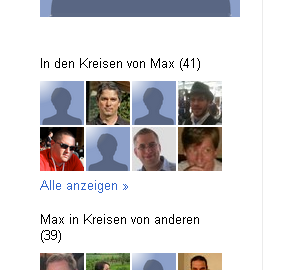
Kontakte in "Circles" finden

Kontakte in "Circles" finden
Google setzt auf JSON / dynamisches Javascript
1: var OZ_initData = 2: ... 3: ,""] 4: ,1,,1] 5: ,[[41,[["113771019406524834799","/113771019406524834799",...,"Paul Boldra"] 6: ,["101868469434747579306","/101868469434747579306",...,"Curtis Poe"] 7: ,["114091227580471410039","/114091227580471410039",...,"James theorbtwo Mastros"] 8: ,["116195765101222598270","/116195765101222598270",...,"Michael Kröll"] 9: ...
Kontakte in "Circles" finden
Google setzt auf JSON / dynamisches Javascript
1: var OZ_initData = 2: ... 3: ,""] 4: ,1,,1] 5: ,[[41,[["113771019406524834799","/113771019406524834799",...,"Paul Boldra"]
Wir wollen
1: OZ_initData["5"][3][0]
Relevante Module

Relevante Module

Relevante Module

Relevante Module

Relevante Module

Relevante Module

Relevante Module

Relevante Module

Relevante Module

Relevante Module
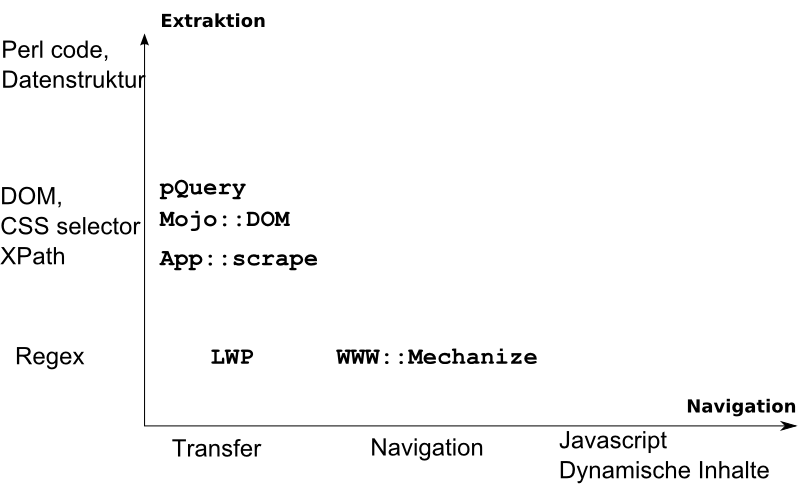
Relevante Module
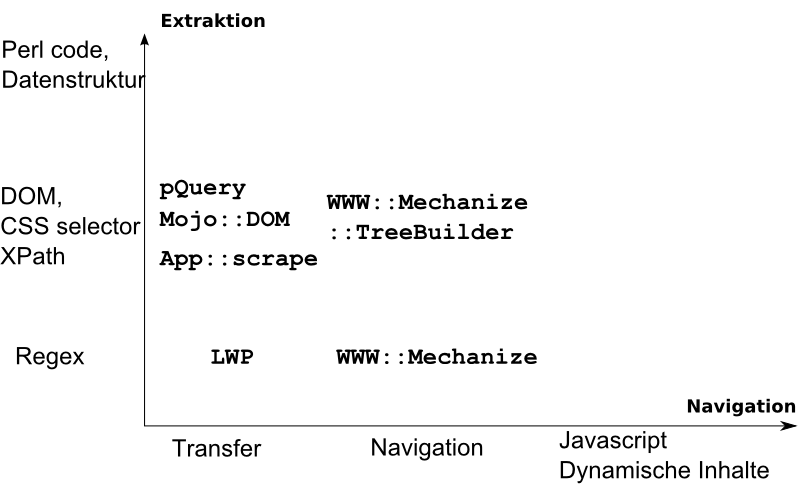
Relevante Module
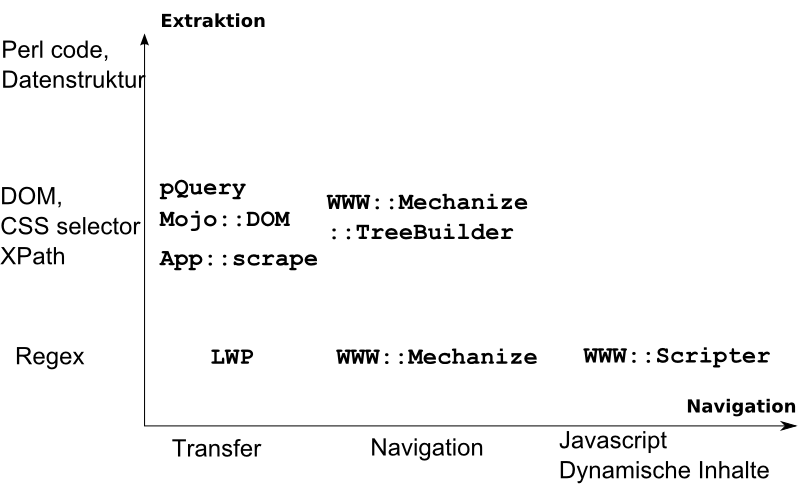
Relevante Module
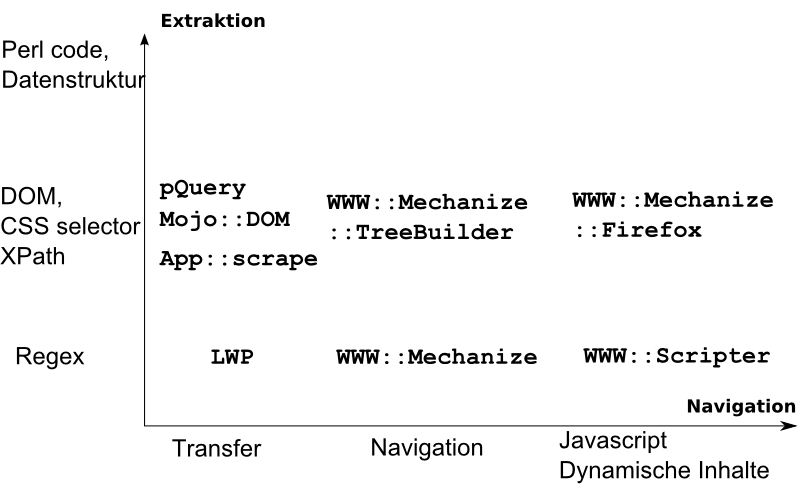
Relevante Module
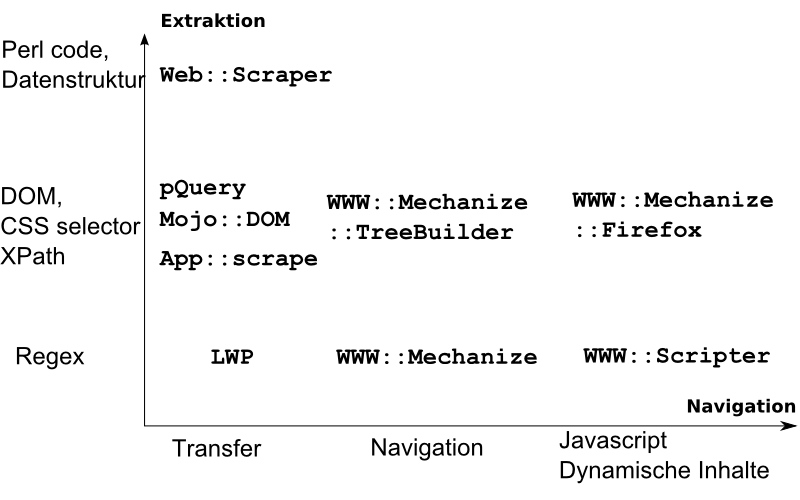
Relevante Module

Der eigene Scraper
Die Arbeit der anderen
Tatsuhiko Miyagawa
-
HTML::Selector::XPath - für CSS3 Selektoren
-
HTML::AutoPagerize - mehrseitige Suchergebnisse